[LeetCode][287. Find the Duplicate Number] 9 Approaches:Brute Force, Count, Hash, In-place Marked, Sorting, Index Sort, Binary Search, Bit Manipulation, Fast Slow Pointers
By Long Luo
This article is the solution 9 Approaches:Brute Force, Count, Hash, In-place Marked, Sorting, Index Sort, Binary Search, Bit Manipulation, Fast Slow Pointers of Problem 287. Find the Duplicate Number.
Here are 9 approaches to solve this problem in Java, which is Brute Force, Count, Hash, In-place Marked, Sorting, Index Sort, Binary Search, Bit Manipulation, Fast Slow Pointers.
Inspired by @user2670f and his solution [C++] 7 Different solutions to this problem (with relaxed constraints) , I added 3 more approaches.
Brute Force (2 Loops)
Since solve the problem without modifying the array nums and uses only constant extra space, we can use Brute Force to solve it.
It’s easy to use 2 loops to do it, but the time complexity is \(O(n^2)\), so it wouldn’t accepted as timeout.1
2
3
4
5
6
7
8
9
10
11
12
13// 2 Loops
public static int findDuplicate_2loops(int[] nums) {
int len = nums.length;
for (int i = 0; i < len; i++) {
for (int j = i + 1; j < len; j++) {
if (nums[i] == nums[j]) {
return nums[i];
}
}
}
return len;
}
Analysis
- Time Complexity: \(O(n^2)\)
- Space Complexity: \(O(1)\)
Count
Count the frequency of the num in the array.
With extra \(O(n)\) space, without modifying the input.1
2
3
4
5
6
7
8
9
10
11
12public static int findDuplicate(int[] nums) {
int len = nums.length;
int[] cnt = new int[len + 1];
for (int i = 0; i < len; i++) {
cnt[nums[i]]++;
if (cnt[nums[i]] > 1) {
return nums[i];
}
}
return len;
}
Analysis
- Time Complexity: \(O(n)\)
- Space Complexity: \(O(n)\)
Hash
Using a \(\texttt{HashSet}\) to record the occurrence of each number.
With extra \(O(n)\) space, without modifying the input.1
2
3
4
5
6
7
8
9
10
11public static int findDuplicate_set(int[] nums) {
Set<Integer> set = new HashSet<>();
int len = nums.length;
for (int i = 0; i < len; i++) {
if (!set.add(nums[i])) {
return nums[i];
}
}
return len;
}
Analysis
- Time Complexity: \(O(n)\)
- Space Complexity: \(O(n)\)
Marking visited value within the array
Since all values of the array are between \([1 \dots n]\) and the array size is \(n+1\), while scanning the array from left to right, we set the \(\textit{nums}[n]\) to its negative value.
With extra \(O(1)\) space, with modifying the input.1
2
3
4
5
6
7
8
9
10
11
12
13// Visited
public static int findDuplicate_mark(int[] nums) {
int len = nums.length;
for (int num : nums) {
int idx = Math.abs(num);
if (nums[idx] < 0) {
return idx;
}
nums[idx] = -nums[idx];
}
return len;
}
Analysis
- Time Complexity: \(O(n)\)
- Space Complexity: \(O(1)\)
Sort
Sorting the array first, then use a loop from \(1\) to \(n\).
With extra \(O(nlogn)\) space, modifying the input.1
2
3
4
5
6
7
8
9
10
11public static int findDuplicate_sort(int[] nums) {
Arrays.sort(nums);
int len = nums.length;
for (int i = 1; i < len; i++) {
if (nums[i] == nums[i - 1]) {
return nums[i];
}
}
return len;
}
Analysis
- Time Complexity: \(O(nlogn)\)
- Space Complexity: \(O(logn)\)
Index Sort
If the array is sorted, the value of each array element is its index value \(index + 1\), then we can do this:
- If \(\textit{nums}[i] == i + 1\), it means that the order has been sorted, then skip, \(i++\);
- If \(\textit{nums}[i] == \textit{nums}[\textit{nums}[i] - 1]\), it means that there is already a value at the correct index, then this value is a duplicated element;
- If none of the above is satisfied, exchange the values of \(\textit{nums}[i]\) and \(\textit{nums}[\textit{nums}[i] - 1]\).
With extra \(O(logn)\) space, with modifying the input.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// Index Sort
// n + 1 numbers in n.
public static int findDuplicate_index_sort(int[] nums) {
int len = nums.length;
for (int i = 0; i < len; ) {
int n = nums[i];
if (n == i + 1) {
i++;
} else if (n == nums[n - 1]) {
return n;
} else {
nums[i] = nums[n - 1];
nums[n - 1] = n;
}
}
return 0;
}
Analysis
- Time Complexity: \(O(n)\)
- Space Complexity: \(O(1)\)
Binary Search
Note that the key is to find an integer in the array \([1, 2, \dots, n]\) instead of finding an integer in the input array.
We can use the binary search algorithm, each round we guess one number, then scan the input array, narrow the search range, and finally get the answer.
According to the Pigeonhole Principle, \(n + 1\) integers, placed in an array of length \(n\), at least \(1\) integer will be repeated.
So guess a number first(the number \(mid\) in the valid range \([left, right]\)), count the elements of the array which is less than or equal to \(mid\) in the array.
- If \(cnt\) is strictly greater than \(mid\). According to the Pigeonhole Principle, repeated elements are in the interval \([left, mid]\);
- Otherwise, the repeated element is in the interval \([mid + 1, right]\).
With extra \(O(1)\) space, without modifying the input.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22public static int findDuplicate_bs(int[] nums) {
int len = nums.length;
int low = 1;
int high = len - 1;
while (low < high) {
int mid = low + (high - low) / 2;
int cnt = 0;
for (int i = 0; i < len; i++) {
if (nums[i] <= mid) {
cnt++;
}
}
if (cnt <= mid) {
low = mid + 1;
} else {
high = mid;
}
}
return low;
}
Analysis
- Time Complexity: \(O(nlogn)\)
- Space Complexity: \(O(1)\)
Bit
This method is convert all the numbers to binary numbers. If we can get each digit of the repeated number in binary, we can rebuild the repeated number.
Count all the bits of \([1, n]\) and array numbers as \(1\) respectively, and then restore them bit by bit to get this repeated number.
For example, the \(i\)th digit, note that in the \(\textit{nums}\) array, the sum of all the elements whose ith digit is \(1\) is \(x\) as convert the number to binary.
As the range \([1, n]\), we can also count the sum of the number whose \(i\)th digit is \(1\), we denoted it \(y\).
We can easily get that \(x > y\).
The following table lists whether each bit in the binary of each number is \(1\) or \(0\) and what the \(x\) and \(y\) of the corresponding bit are:
| 1 | 3 | 4 | 2 | 2 | x | y | |
|---|---|---|---|---|---|---|---|
| Bit 0 | 1 | 1 | 0 | 0 | 0 | 2 | 2 |
| Bit 1 | 1 | 0 | 1 | 1 | 1 | 3 | 2 |
| Bit 2 | 0 | 0 | 1 | 0 | 0 | 1 | 1 |
From the table, we found that only the \(1\)th bit \(x > y\), so after bitwise restoration \(\textit{target}=(010)_2=(2)_{10}\), which is the answer.
The proof of correctness is actually similar to method \(1\). We can consider the change of the number \(x\) of the \(i\)-th in different example arrays.
If \(\textit{target}\) appears twice in the test case array, the rest of the numbers appear once, and the \(i\)th bit of \(\textit{target}\) is \(1\), then the \(\textit{nums}\) array x, is exactly one greater than y. If bit \(i\) of is \(0\), then both are equal.
If \(\textit{target}\) appears three or more times in the array of test cases, then there must be some numbers that are not in the \(\textit{nums}\) array. At this time, it is equivalent to replacing these with \(\textit{target}\), we consider the impact on \(x\) when replacing:
If the \(i\)-th bit of the number to be replaced is \(1\), and the \(i\)-th bit of \(\textit{target}\) is \(1\): \(x\) remains unchanged, \(x > y\).
If the \(i\)-th bit of the number being replaced is \(0\), and the \(i\)-th bit of \(\textit{target}\) is \(1\): x plus one, \(x > y\).
If the i-th bit of the number to be replaced is \(1\), and the \(i\)-th bit of \(\textit{target}\) is \(0\): \(x\) minus one, \(x \le y\).
If the \(i\)-th bit of the number to be replaced is \(0\), and the \(i\)-th bit of \(\textit{target}\) is \(0\): x remains unchanged, satisfying \(x \le y\).
Therefore, if the ith bit of \(\textit{target}\) is \(1\), then after each replacement, only \(x\) will be unchanged or increased. If it is \(0\), only \(x\) will be unchanged or decreased.
When \(x > y\), the ith bit of \(\textit{target}\) is \(1\), otherwise it is \(0\). We only need to restore this repeated number bitwise.
With extra \(O(nlogn)\) space, without modifying the input.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25public static int findDuplicate_bit(int[] nums) {
int n = nums.length;
int ans = 0;
int bit_max = 31;
while (((n - 1) >> bit_max) == 0) {
bit_max -= 1;
}
for (int bit = 0; bit <= bit_max; ++bit) {
int x = 0, y = 0;
for (int i = 0; i < n; ++i) {
if ((nums[i] & (1 << bit)) != 0) {
x += 1;
}
if (i >= 1 && ((i & (1 << bit)) != 0)) {
y += 1;
}
}
if (x > y) {
ans |= 1 << bit;
}
}
return ans;
}
Analysis
- Time Complexity: \(O(nlogn)\)
- Space Complexity: \(O(1)\)
Fast Slow Pointers
This problem is as same as 142. Linked List Cycle II, you can refer to this solution for the explanation of the slow fast pointer approach to solve this problem.
The key is to understand how to treat the input array as a linked list.
Take the array \([1,3,4,2]\) as an example, the index of this array is \([0, 1, 2, 3]\), we can map the index to the \(\textit{nums}[n]\).
\[ 0 \to 1 \to 3 \to 2 \to 4 \to 3 \to 2 \]
Start from \(\textit{nums}[n]\) as a new index, and so on, until the index exceeds the bounds. This produces a sequence similar to a linked list.
\[ 0 \to 1 \to 3 \to 2 \to 4 \to null \]
If there are a repeated numbers in the array, take the array \([1,3,4,2,2]\) as an example,
\[ 0 \to 1 \to 3 \to 2 \to 4 \to 3 \to 2 \to 4 \to 2 \]
Similarly, a linked list is like that:
\[ 0 \to 1 \to 3 \to 2 \to 4 \to 2 \to 4 \to 2 \to \dots \]
Here \(2 \to 4\) is a cycle, then this linked list can be abstracted as the following figure: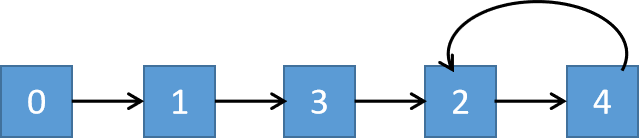
With extra \(O(n)\) space, without modifying the input.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16public int findDuplicate_fastSlow(int[] nums) {
int slow = 0;
int fast = 0;
do {
slow = nums[slow];
fast = nums[nums[fast]];
} while (slow != fast);
slow = 0;
while (slow != fast) {
slow = nums[slow];
fast = nums[fast];
}
return slow;
}
Analysis
- Time Complexity: \(O(n)\)
- Space Complexity: \(O(1)\)
All suggestions are welcome. If you have any query or suggestion please comment below. Please upvote👍 if you like💗 it. Thank you:-)
Explore More Leetcode Solutions. 😉😃💗